
Machine Learning in Alteryx with PyCaret
Machine Learning in Alteryx with PyCaret
A step-by-step tutorial on training and deploying machine learning models in Alteryx Designer using PyCaret
Introduction
In this tutorial, I will show you how you can train and deploy machine learning pipelines in a very popular ETL tool Alteryx using PyCaret — an open-source, low-code machine learning library in Python. The Learning Goals of this tutorial are:
👉 What is PyCaret and how to get started?
👉 What is Alteryx Designer and how to set it up?
👉 Train end-to-end machine learning pipeline in Alteryx Designer including data preparation such as missing value imputation, one-hot-encoding, scaling, transformations, etc.
👉 Deploy trained pipeline and generate inference during ETL.
PyCaret
PyCaret is an open-source, low-code machine learning library and end-to-end model management tool built-in Python for automating machine learning workflows. PyCaret is known for its ease of use, simplicity, and ability to quickly and efficiently build and deploy end-to-end machine learning pipelines. To learn more about PyCaret, check out their GitHub.
Alteryx Designer
Alteryx Designer is a proprietary tool developed by **Alteryx** and is used for automating every step of analytics, including data preparation, blending, reporting, predictive analytics, and data science. You can access any data source, file, application, or data type, and experience the simplicity and power of a self-service platform with 260+ drag-and-drop building blocks. You can download the one-month free trial version of Alteryx Designer from here.
Tutorial Pre-Requisites:
For this tutorial, you will need two things. The first one being the Alteryx Designer which is a desktop software that you can download from here. Second, you need Python. The easiest way to get Python is to download Anaconda Distribution. To download that, click here.
👉We are ready now
Open Alteryx Designer and click on File → New Workflow
On the top, there are tools that you can drag and drop on the canvas and execute the workflow by connecting each component to one another.
Dataset
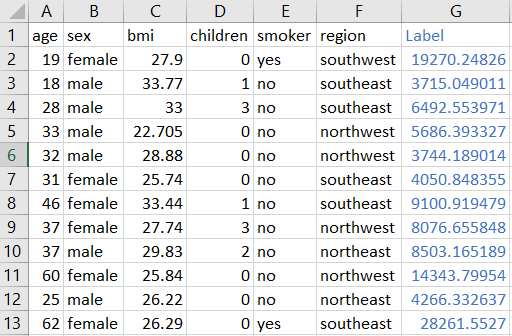
For this tutorial, I am using a regression dataset from PyCaret’s repository called insurance. You can download the data from here.
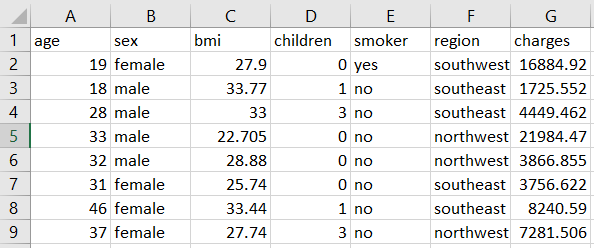
I will create two separate Alteryx workflows. First one for model training and selection and the second one for scoring the new data using the trained pipeline.
👉 Model Training & Selection
Let’s first read the CSV file from the **Input Data **tool followed by a **Python Script. **Inside the Python script execute the following code:
This script is importing the regression module from pycaret, then initializing the setup function which automatically handles train_test_split and all the data preparation tasks such as missing value imputation, scaling, feature engineering, etc. compare_models trains and evaluates all the estimators using kfold cross-validation and returns the best model.
pull function calls the model performance metric as a Dataframe which is then saved as results.csv on a drive and also written to the first anchor of Python tool in Alteryx (so that you can view results on screen).
Finally, save_model saves the entire transformation pipeline including the best model as a pickle file.
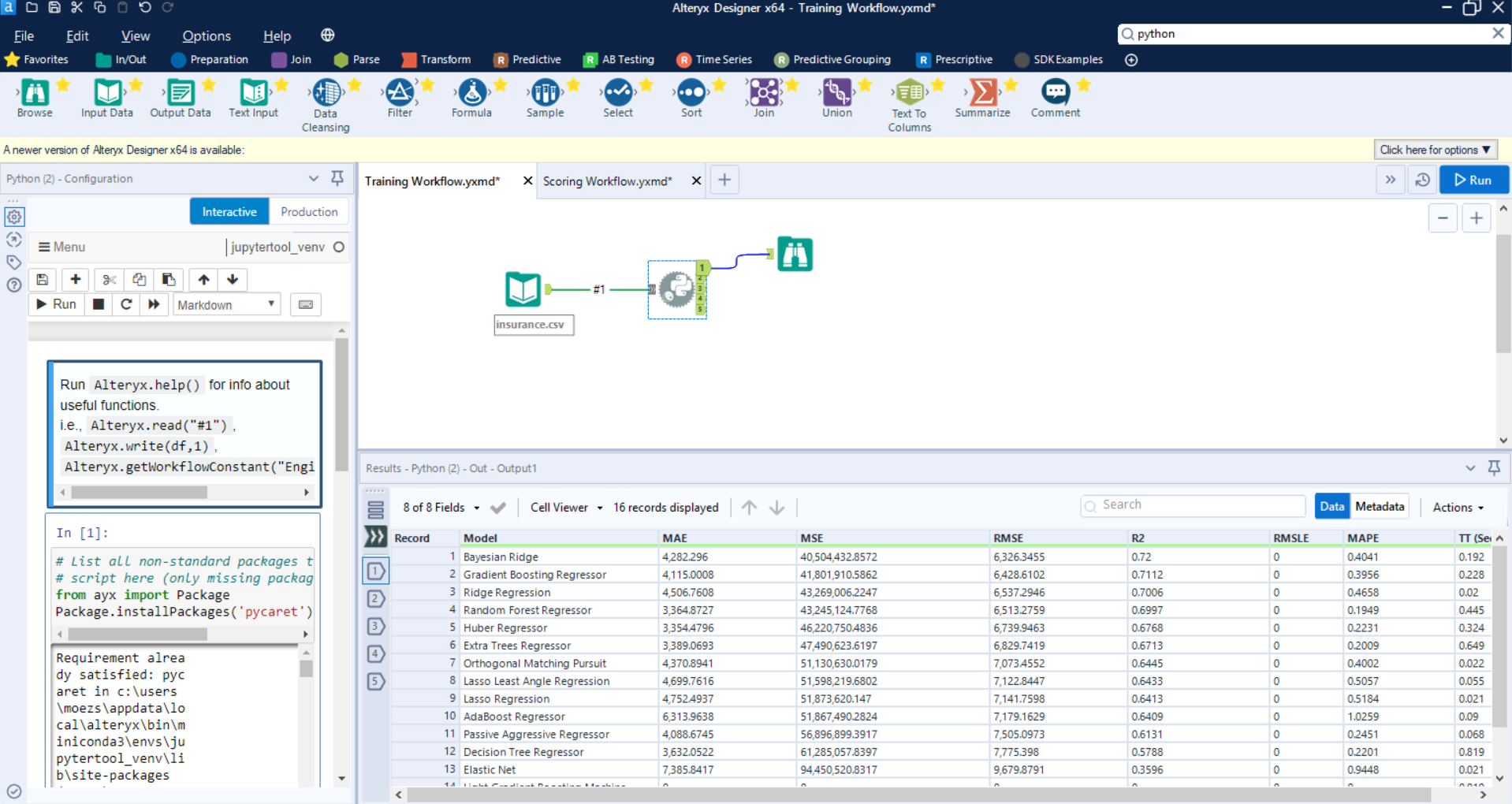
When you successfully execute this workflow, you will generate pipeline.pkl and results.csv file. You can see the output of the best models and their cross-validated metrics on-screen as well.
This is what results.csv contains:
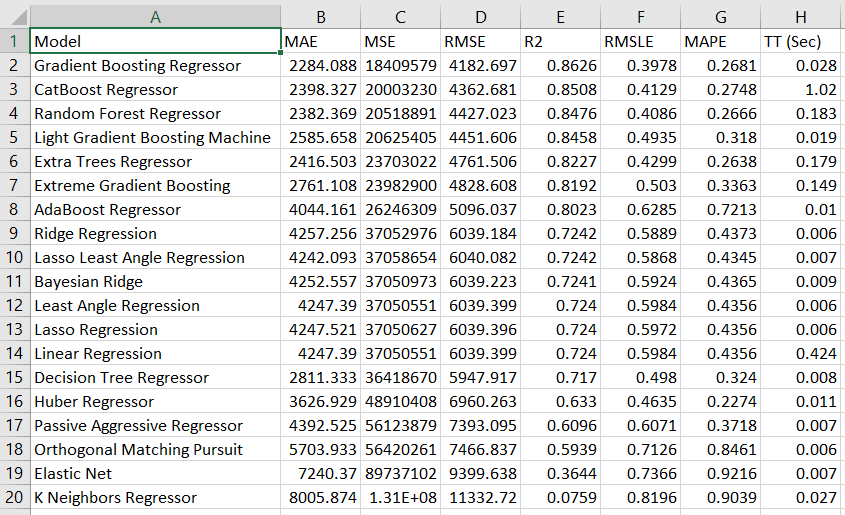
These are the cross-validated metrics for all the models. The best model, in this case, is Gradient Boosting Regressor.
👉 Model Scoring
We can now use our pipeline.pkl to score on the new dataset. Since I do not have a separate dataset for ***insurance.csv without the label, ***what I will do is drop the target column i.e. charges, and then generate predictions using the trained pipeline.
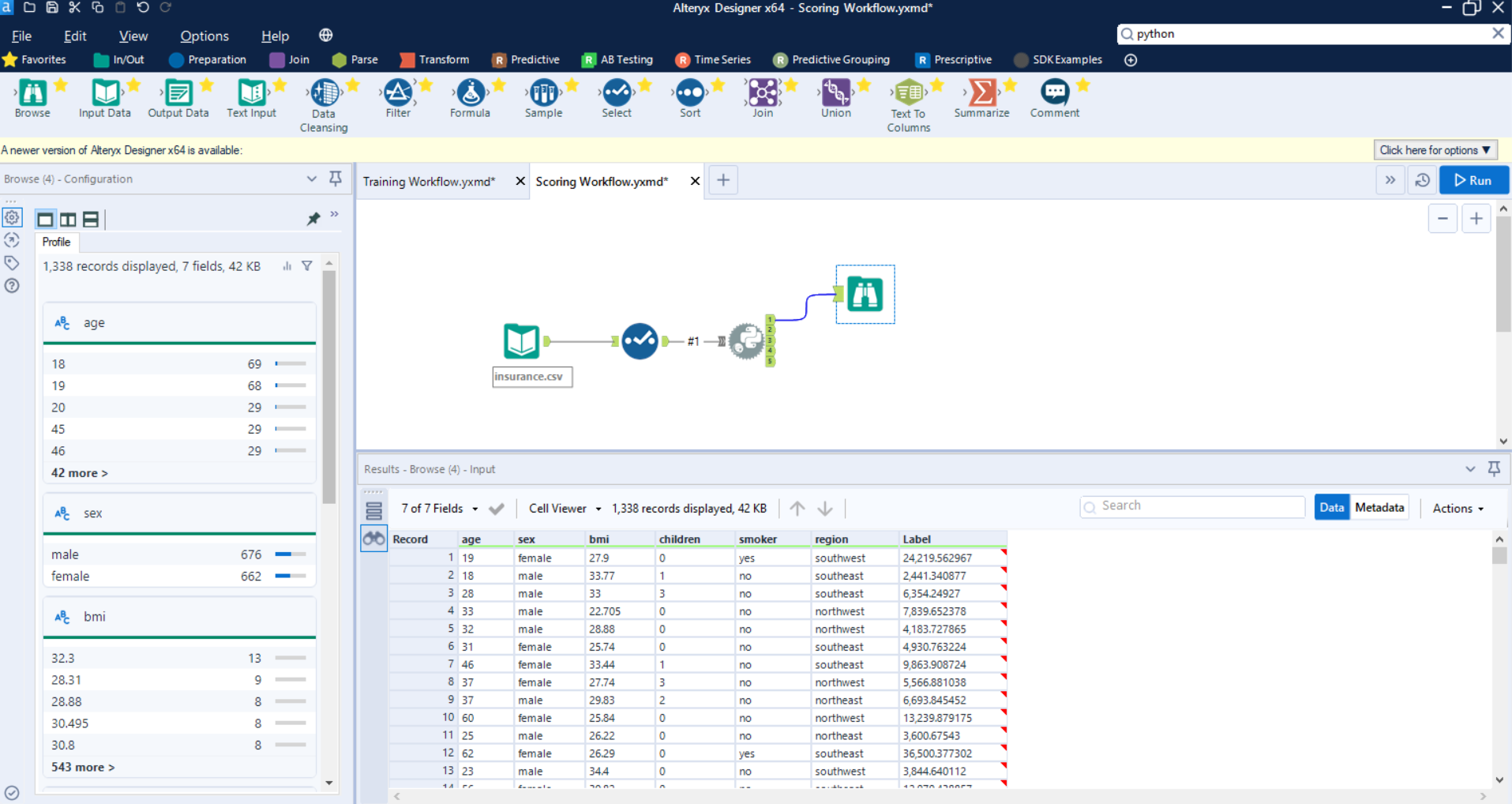
I have used the **Select Tool **to remove the target column i.e. charges . In the Python script execute the following code:
When you successfully execute this workflow, it will generate predictions.csv.
Coming Soon!
Next week I will take a deep dive and focus on more advanced functionalities of PyCaret that you can use within Alteryx to enhance your machine learning workflows. If you would like to be notified automatically, you can follow me on Medium, LinkedIn, and Twitter.


There is no limit to what you can achieve using this lightweight workflow automation library in Python. If you find this useful, please do not forget to give us ⭐️ on our GitHub repository.
To hear more about PyCaret follow us on LinkedIn and Youtube.
Join us on our slack channel. Invite link here.
Important Links
Documentation Blog GitHub StackOverflow Install PyCaret Notebook Tutorials Contribute in PyCaret
More PyCaret related tutorials:
Machine Learning in KNIME with PyCaret A step-by-step guide on training and deploying end-to-end machine learning pipelines in KNIME using PyCarettowardsdatascience.com Easy MLOps with PyCaret + MLflow A beginner-friendly, step-by-step tutorial on integrating MLOps in your Machine Learning experiments using PyCarettowardsdatascience.com Write and train your own custom machine learning models using PyCaret towardsdatascience.com Build with PyCaret, Deploy with FastAPI *A step-by-step, beginner-friendly tutorial on how to build an end-to-end Machine Learning Pipeline with PyCaret and…*towardsdatascience.com Time Series Anomaly Detection with PyCaret A step-by-step tutorial on unsupervised anomaly detection for time series data using PyCarettowardsdatascience.com Supercharge your Machine Learning Experiments with PyCaret and Gradio A step-by-step tutorial to develop and interact with machine learning pipelines rapidlytowardsdatascience.com Multiple Time Series Forecasting with PyCaret A step-by-step tutorial on forecasting multiple time series using PyCarettowardsdatascience.com
Last updated
Was this helpful?