
PyCaret 2.3.6 is Here! Learn What’s New?
PyCaret 2.3.6 is Here! Learn What’s New? From EDA to Deployment to AI Fairness — By far the biggest release of PyCaret
🚀 Introduction
💻 Installation
pip install pycaretpip install pycaret[full]📈 Dashboard
# load dataset
from pycaret.datasets import get_data
data = get_data('iris')
# init setupfrom pycaret.classification import *
s = setup(data, target = 'species', session_id = 123)
# train model
lr = create_model('lr')
# generate dashboard
dashboard(lr)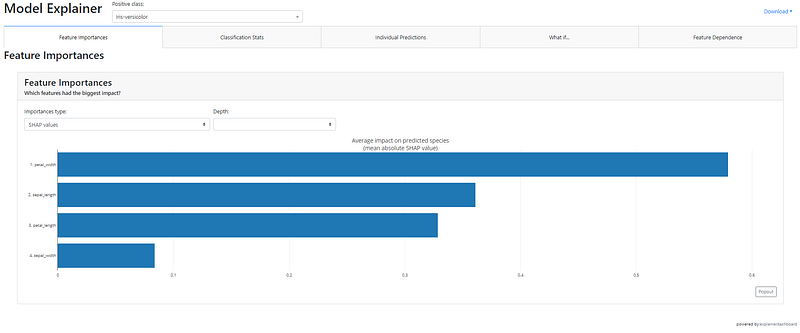
📊 Exploratory Data Analysis (EDA)

🚊 Convert Model

☑️ Check Fairness

📩 Create Web API


Video Demo:
🚢 Create Docker

💻 Create Web Application

🎰 Monitor Drift of ML Models


🔨 Plot Model is now more configurable

🏆Optimize Threshold

📚 New Documentation
🔗 Important Links
Last updated
Was this helpful?