> For the complete documentation index, see [llms.txt](https://pycaret.gitbook.io/docs/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://pycaret.gitbook.io/docs/learn-pycaret/official-blog/5-things-you-dont-know-about-pycaret.md).
# 5 things you dont know about PyCaret
### 5 things you don’t know about PyCaret
#### by Moez Ali

### PyCaret
PyCaret is an open source machine learning library in Python to train and deploy supervised and unsupervised machine learning models in a **low-code** environment. It is known for its ease of use and efficiency.
In comparison with the other open source machine learning libraries, PyCaret is an alternate low-code library that can be used to replace hundreds of lines of code with a few words only.
If you haven’t used PyCaret before or would like to learn more, a good place to start is [here](https://towardsdatascience.com/announcing-pycaret-an-open-source-low-code-machine-learning-library-in-python-4a1f1aad8d46).
> ## “After talking to many data scientists who use PyCaret on a daily basis, I have shortlisted 5 features of PyCaret that are lesser known but they extremely powerful.” — Moez Ali
### 👉You can tune “n parameter” in unsupervised experiments
In unsupervised machine learning the “n parameter” i.e. the number of clusters for clustering experiments, the fraction of the outliers in anomaly detection, and the number of topics in topic modeling, is of fundamental importance.
When the eventual objective of the experiment is to predict an outcome (classification or regression) using the results from the unsupervised experiments, then the tune\_model() function in the \*\*pycaret.clustering **module**, \*\*the **pycaret.anomaly module,** and the \*\*pycaret.nlp \*\*module \*\*\*\*comes in very handy.
To understand this, let’s see an example using the “[Kiva](https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/kiva.csv)” dataset.

This is a micro-banking loan dataset where each row represents a borrower with their relevant information. Column ‘en’ captures the loan application text of each borrower, and the column ‘status’ represents whether the borrower defaulted or not (default = 1 or no default = 0).
You can use \*\*tune\_model \*\*function in \*\*pycaret.nlp \*\*to optimize \*\*num\_topics \*\*parameter based on the target variable of supervised experiment (i.e. predicting the optimum number of topics required to improve the prediction of the final target variable). You can define the model for training using **estimator** parameter (‘xgboost’ in this case). This function returns a trained topic model and a visual showing supervised metrics at each iteration.

### 👉You can improve results from hyperparameter tuning by increasing “n\_iter”
The \*\*tune\_model \*\*function in the \*\*pycaret.classification \*\*module and the **pycaret.regression** module employs random grid search over pre-defined grid search for hyper-parameter tuning. Here the default number of iterations is set to 10.
Results from \*\*tune\_model \*\*may not necessarily be an improvement on the results from the base models created using \*\*create\_model. \*\*Since the grid search is random, you can increase the \*\*n\_iter \*\*parameter to improve the performance. See example below:

### 👉You can programmatically define data types in the setup function
When you initialize the \*\*setup **function**, \*\*you will be asked to confirm data types through a user input. More often when you run the scripts as a part of workflows or execute it as remote kernels (for e.g. Kaggle Notebooks), then in such case, it is required to provide the data types programmatically rather than through the user input box.
See example below using “[insurance](https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/insurance.csv)” dataset.
the **silent** parameter is set to True to avoid input, \*\*categorical\_features \*\*parameter takes the name of categorical columns as string, and \*\*numeric\_features \*\*parameter takes the name of numeric columns as a string.
### 👉You can ignore certain columns for model building
On many occasions, you have features in dataset that you do not necessarily want to remove but want to ignore for training a machine learning model. A good example would be a clustering problem where you want to ignore certain features during cluster creation but later you need those columns for analysis of cluster labels. In such cases, you can use the \*\*ignore\_features \*\*parameter within the \*\*setup \*\*to ignore such features.
In the example below, we will perform a clustering experiment and we want to ignore **‘Country Name’** and **‘Indicator Name’**.
### 👉You can optimize the probability threshold % in binary classification
In classification problems, the cost of **false positives** is almost never the same as the cost of **false negatives**. As such, if you are optimizing a solution for a business problem where **Type 1** and **Type 2** errors have a different impact, you can optimize your classifier for a probability threshold value to optimize the custom loss function simply by defining the cost of true positives, true negatives, false positives and false negatives separately. By default, all classifiers have a threshold of 0.5.
See example below using “[credit](https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/credit.csv)” dataset.
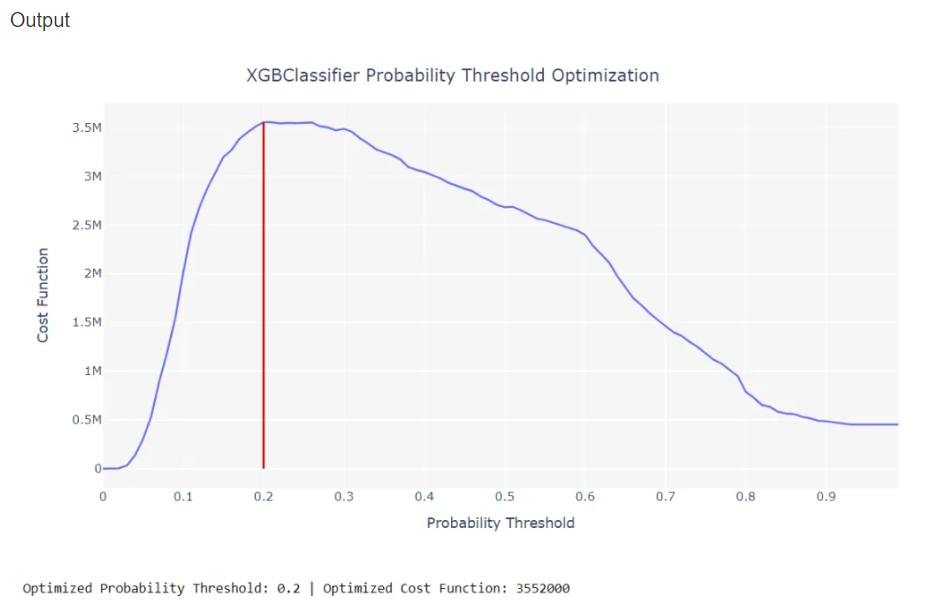
You can then pass \*\*0.2 \*\*as \*\*probability\_threshold \*\*parameter in \*\*predict\_model \*\*function to use 0.2 as a threshold for classifying positive class. See example below:
### PyCaret 2.0.0 is coming!
We have received overwhelming support and feedback from the data science community. We are actively working on improving PyCaret and preparing for our next release. **PyCaret 2.0.0 will be bigger and better**. If you would like to share your feedback and help us improve further, you may [fill this form](https://www.pycaret.org/feedback) on the website or leave a comment on our [GitHub ](https://www.github.com/pycaret/)or [LinkedIn](https://www.linkedin.com/company/pycaret/) page.
Follow our [LinkedIn](https://www.linkedin.com/company/pycaret/) and subscribe to our [YouTube](https://www.youtube.com/channel/UCxA1YTYJ9BEeo50lxyI_B3g) channel to learn more about PyCaret.
### Want to learn about a specific module?
As of the first release 1.0.0, PyCaret has the following modules available for use. Click on the links below to see the documentation and working examples in Python.
[Classification](https://www.pycaret.org/classification) [Regression ](https://www.pycaret.org/regression)[Clustering](https://www.pycaret.org/clustering) [Anomaly Detection ](https://www.pycaret.org/anomaly-detection)[Natural Language Processing](https://www.pycaret.org/nlp) [Association Rule Mining](https://www.pycaret.org/association-rules)
### Also see:
PyCaret getting started tutorials in Notebook:
[Classification](https://www.pycaret.org/clf101) [Regression](https://www.pycaret.org/reg101) [Clustering](https://www.pycaret.org/clu101) [Anomaly Detection](https://www.pycaret.org/anom101) [Natural Language Processing](https://www.pycaret.org/nlp101) [Association Rule Mining](https://www.pycaret.org/arul101)
### Would you like to contribute?
PyCaret is an open source project. Everybody is welcome to contribute. If you would like to contribute, please feel free to work on [open issues](https://github.com/pycaret/pycaret/issues). Pull requests are accepted with unit tests on dev-1.0.1 branch.
Please give us ⭐️ on our [GitHub repo](https://www.github.com/pycaret/pycaret) if you like PyCaret.
Medium: [https://medium.com/@moez\_62905/](https://medium.com/@moez_62905/machine-learning-in-power-bi-using-pycaret-34307f09394a)
LinkedIn:
Twitter:
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://pycaret.gitbook.io/docs/learn-pycaret/official-blog/5-things-you-dont-know-about-pycaret.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.