> For the complete documentation index, see [llms.txt](https://pycaret.gitbook.io/docs/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://pycaret.gitbook.io/docs/learn-pycaret/official-blog/deploy-pycaret-and-streamlit-on-aws-fargate.md).
# Deploy PyCaret and Streamlit on AWS Fargate
### Deploy PyCaret and Streamlit app using AWS Fargate — serverless infrastructure
#### by Moez Ali

### RECAP
In our [last post](https://towardsdatascience.com/deploy-machine-learning-app-built-using-streamlit-and-pycaret-on-google-kubernetes-engine-fd7e393d99cb), we demonstrated how to develop a machine learning pipeline using PyCaret and serve it as a Streamlit web application deployed onto Google Kubernetes Engine. If you haven’t heard about PyCaret before, you can read this [announcement](https://towardsdatascience.com/announcing-pycaret-an-open-source-low-code-machine-learning-library-in-python-4a1f1aad8d46) to get started.
In this tutorial, we will use the same web app and machine learning pipeline that we had built previously and demonstrate how to deploy it using AWS Fargate which is a serverless compute for containers.
By the end of this tutorial, you will be able to build and host a fully functional containerized web app on AWS without provisioning any server infrastructure.
### 👉 Learning Goals of this Tutorial
* What is a Container? What is Docker? What is Kubernetes?
* What is Amazon Elastic Container Service (ECS), AWS Fargate and serverless deployment?
* Build and push a Docker image onto Amazon Elastic Container Registry.
* Deploy web app using serverless infrastructure i.e. AWS Fargate.
This tutorial will cover the entire workflow starting from building a docker image locally, uploading it onto Amazon Elastic Container Registry, creating a cluster and then defining and executing task using AWS-managed infrastructure.
In the past, we have covered deployment on other cloud platforms such as Azure and Google. If you are interested in learning more about those, you can read the following tutorials:
* [Deploy Streamlit app onto Google Kubernetes Engine](https://towardsdatascience.com/deploy-machine-learning-app-built-using-streamlit-and-pycaret-on-google-kubernetes-engine-fd7e393d99cb)
* [Build and deploy machine learning web app using PyCaret and Streamlit](https://towardsdatascience.com/build-and-deploy-machine-learning-web-app-using-pycaret-and-streamlit-28883a569104)
* [Deploy Machine Learning Pipeline on AWS Fargate](https://towardsdatascience.com/deploy-machine-learning-pipeline-on-aws-fargate-eb6e1c50507)
* [Deploy Machine Learning Pipeline on Google Kubernetes Engine](https://towardsdatascience.com/deploy-machine-learning-model-on-google-kubernetes-engine-94daac85108b)
* [Deploy Machine Learning Pipeline on AWS Web Service](https://towardsdatascience.com/deploy-machine-learning-pipeline-on-cloud-using-docker-container-bec64458dc01)
* [Build and deploy your first machine learning web app on Heroku PaaS](https://towardsdatascience.com/build-and-deploy-your-first-machine-learning-web-app-e020db344a99)
### 💻 Toolbox for this tutorial
### PyCaret
[PyCaret](https://www.pycaret.org/) is an open source, low-code machine learning library in Python that is used to train and deploy machine learning pipelines and models into production. PyCaret can be installed easily using pip.
```
pip install pycaret
```
### Streamlit
[Streamlit](https://www.streamlit.io/) is an open-source Python library that makes it easy to build beautiful custom web-apps for machine learning and data science. Streamlit can be installed easily using pip.
```
pip install streamlit
```
### Docker Toolbox for Windows 10 Home
[Docker](https://www.docker.com/)\*\* \*\*is a tool designed to make it easier to create, deploy, and run applications by using containers. Containers are used to package up an application with all of its necessary components, such as libraries and other dependencies, and ship it all out as one package. If you haven’t used docker before, this tutorial also covers the installation of Docker Toolbox (legacy) on **Windows 10 Home**. In the [previous tutorial](https://towardsdatascience.com/deploy-machine-learning-pipeline-on-cloud-using-docker-container-bec64458dc01) we covered how to install Docker Desktop on **Windows 10 Pro edition**.
### Amazon Web Services (AWS)
Amazon Web Services (AWS) is a comprehensive and broadly adopted cloud platform, offered by Amazon. It has over 175 fully-featured services from data centers globally. If you haven’t used AWS before, you can [sign-up](https://aws.amazon.com/) for a free account.
### ✔️Let’s get started…..
### What is a Container?
Before we get into implementation using AWS Fargate, let’s understand what a container is and why we would need one?

Have you ever had the problem where your code works fine on your computer but when a friend tries to run the exact same code, it doesn’t work? If your friend is repeating the exact same steps, they should get the same results, right? The one-word answer to this is \*\**the environment*. \*\*Your friend’s environment is different than yours.
What does an environment include? → The programing language such as Python and all the libraries and dependencies with the exact versions using which application was built and tested.
If we can create an environment that we can transfer to other machines (for example: your friend’s computer or a cloud service provider like Google Cloud Platform), we can reproduce the results anywhere. Hence, \*\*\*a \*\*\*\*container \*\*\*is a type of software that packages up an application and all its dependencies so the application runs reliably from one computing environment to another.
### What is Docker?
Docker is a company that provides software (also called **Docker**) that allows users to build, run and manage containers. While Docker’s container are the most common, there are other less famous *alternatives* such as [LXD](https://linuxcontainers.org/lxd/introduction/) and [LXC](https://linuxcontainers.org/).

Now that you theoretically understand what a container is and how Docker is used to containerize applications, let’s imagine a scenario where you have to run multiple containers across a fleet of machines to support an enterprise level machine learning application with varied workloads during day and night. This is pretty common for real-life and as simple as it may sound, it is a lot of work to do manually.
You need to start the right containers at the right time, figure out how they can talk to each other, handle storage considerations, deal with failed containers or hardware and million other things!
This entire process of managing hundreds and thousands of containers to keep the application up and running is known as **container orchestration**. Don’t get caught up in the technical details yet.
At this point, you must recognize that managing real-life applications require more than one container and managing all of the infrastructure to keep containers up and running is cumbersome, manual and an administrative burden.
This brings us to **Kubernetes**.
### What is Kubernetes?
Kubernetes is an open-source system developed by Google in 2014 for managing containerized applications. In simple words, Kubernetes \*\*\*\*is a system for running and coordinating containerized applications across a cluster of machines.

While Kubernetes is an open-source system developed by Google, almost all major cloud service providers offer Kubernetes as a Managed Service. For example: \*\*Amazon Elastic Kubernetes Service (EKS) **offered by Amazon**, Google Kubernetes Engine (GKE) **offered by Google**, \*\*and \*\*Azure Kubernetes Service (AKS) \*\*offered by Microsoft.
So far we have discussed and understood:
✔️ A ***container***
✔️ Docker
✔️ Kubernetes
Before introducing AWS Fargate, there is only one thing left to discuss and that is Amazon’s own container orchestration service **Amazon Elastic Container Service (ECS).**
### AWS Elastic Container Service (ECS)
Amazon Elastic Container Service (Amazon ECS) is Amazon’s home-grown container orchestration platform. The idea behind ECS is similar to Kubernetes *(both of them are orchestration services)*.
ECS is an AWS-native service, meaning that it is only possible to use on AWS infrastructure. On the other hand, **EKS** is based on Kubernetes, an open-source project which is available to users running on multi-cloud (AWS, GCP, Azure) and even On-Premise.
Amazon also offers a Kubernetes based container orchestration service known as \*\*Amazon Elastic Kubernetes Service (Amazon EKS). \*\*Even though the purpose of ECS and EKS is pretty similar i.e. *orchestrating containerized applications*, there are quite a few differences in pricing, compatibility and security. There is no best answer and the choice of solution depends on the use-case.
Irrespective of whichever container orchestration service you are using (ECS or EKS), there are two ways you can implement the underlying infrastructure:
1. Manually manage the cluster and underlying infrastructure such as Virtual Machines / Servers / (also known as EC2 instances).
2. Serverless — Absolutely no need to manage anything. Just upload the container and that’s it. ← **This is AWS Fargate.**

### AWS Fargate — serverless compute for containers
AWS Fargate is a serverless compute engine for containers that works with both Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS). Fargate makes it easy for you to focus on building your applications. Fargate removes the need to provision and manage servers, lets you specify and pay for resources per application, and improves security through application isolation by design.
Fargate allocates the right amount of compute, eliminating the need to choose instances and scale cluster capacity. You only pay for the resources required to run your containers, so there is no over-provisioning and paying for additional servers.
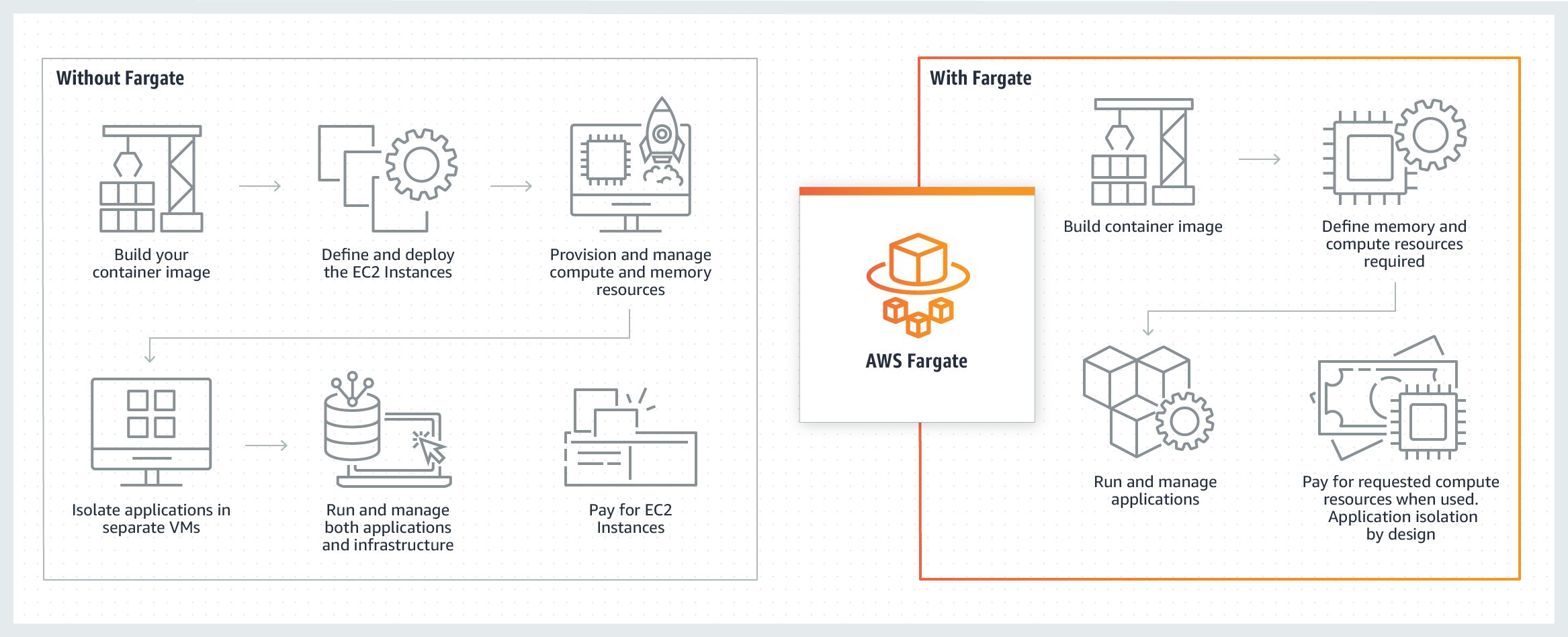
There is no best answer as to which approach is better. The choice between going serverless or manually managing an EC2 cluster depends on the use-case. Some pointers that can assist with this choice include:
**ECS EC2 (Manual Approach)**
* You are all-in on AWS.
* You have a dedicated Ops team in place to manage AWS resources.
* You have an existing footprint on AWS i.e. you are already managing EC2 instances
**AWS Fargate**
* You do not have huge Ops team to manage AWS resources.
* You do not want operational responsibility or want to reduce it.
* Your application is stateless *(A stateless app is an application that does not save client data generated in one session for use in the next session with that client)*.
### Setting the Business Context
An insurance company wants to improve its cash flow forecasting by better predicting patient charges using demographic and basic patient health risk metrics at the time of hospitalization.
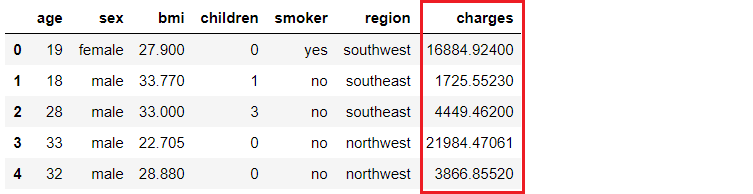
*(*[*data source*](https://www.kaggle.com/mirichoi0218/insurance#insurance.csv)*)*
### Objective
To build and deploy a web application where the demographic and health information of a patient is entered into a web-based form which then outputs a predicted charge amount.
### Tasks
* Train, validate and develop a machine learning pipeline using PyCaret.
* Build a front-end web application with two functionalities: (i) online prediction and (ii) batch prediction.
* Create a Dockerfile
* Create and execute a task to deploy the app using AWS Fargate serverless infrastructure.
Since we have already covered the first two tasks in our [last tutorial](https://towardsdatascience.com/deploy-machine-learning-app-built-using-streamlit-and-pycaret-on-google-kubernetes-engine-fd7e393d99cb), we will quickly recap them and then focus on the remaining items in the list above. If you are interested in learning more about developing a machine learning pipeline in Python using PyCaret and building a web app using a Streamlit framework, please read [this tutorial](https://towardsdatascience.com/build-and-deploy-machine-learning-web-app-using-pycaret-and-streamlit-28883a569104).
### 👉 Task 1 — Model Training and Validation
We are using PyCaret in Python for training and developing a machine learning pipeline which will be used as part of our web app. The Machine Learning Pipeline can be developed in an Integrated Development Environment (IDE) or Notebook. We have used a notebook to run the below code:
When you save a model in PyCaret, the entire transformation pipeline based on the configuration defined in the \*\*setup() \*\*function is created . All inter-dependencies are orchestrated automatically. See the pipeline and model stored in the ‘deployment\_28042020’ variable:

### 👉 Task 2 — Build a front-end web application
Now that our machine learning pipeline and model are ready to start building a front-end web application that can generate predictions on new datapoints. This application will support ‘Online’ as well as ‘Batch’ predictions through a csv file upload. Let’s breakdown the application code into three main parts:
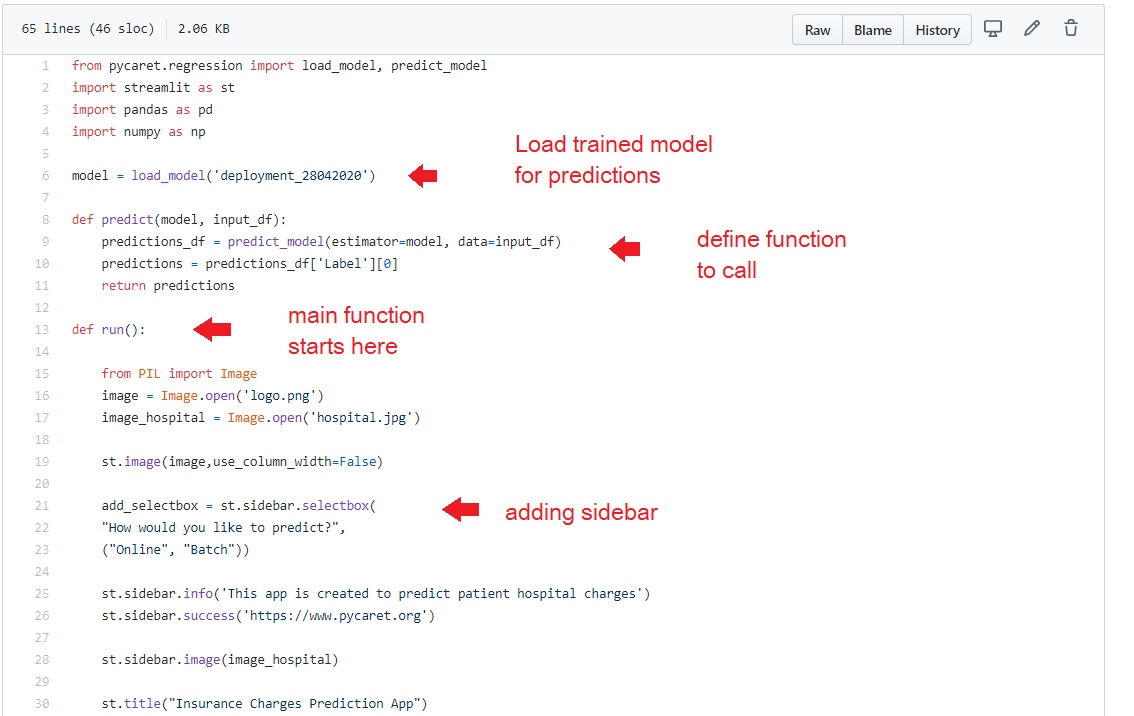
### Header / Layout
This section imports libraries, loads the trained model and creates a basic layout with a logo on top, a jpg image and a dropdown menu on the sidebar to toggle between ‘Online’ and ‘Batch’ prediction.
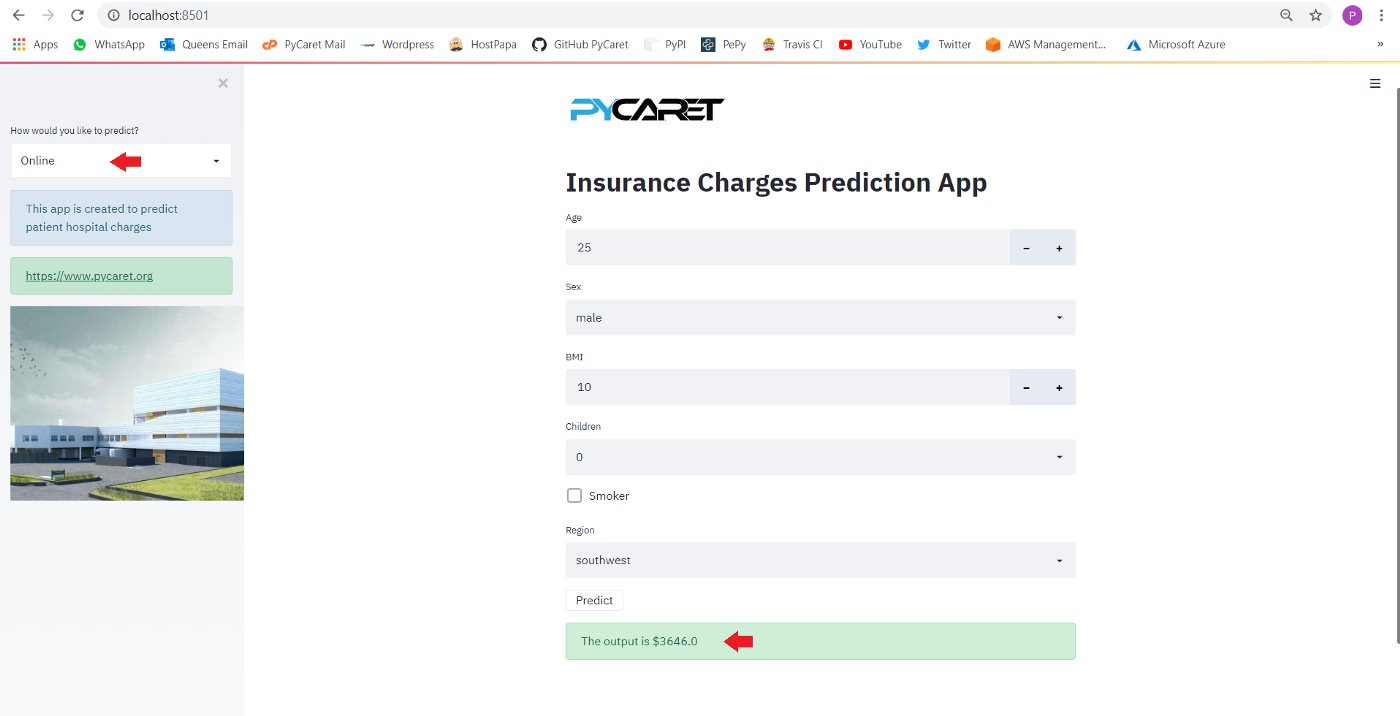
#### Online Predictions
This section deals with the initial app function, Online one-by-one predictions. We are using streamlit widgets such as *number input, text input, drop down menu and checkbox* to collect the datapoints used to train the model such as Age, Sex, BMI, Children, Smoker, Region.

#### Batch Predictions
Predictions by batch is the second layer of the app’s functionality. The **file\_uploader** widget in streamlit is used to upload a csv file and then called the native \*\*predict\_model() \*\*function from PyCaret to generate predictions that are displayed using streamlit’s write() function.

\*\*Testing App \*\*One final step before we deploy the application on AWS Fargate is to test the app locally. Open Anaconda Prompt and navigate to your project folder and execute the following code:
```
streamlit run app.py
```

### 👉 Task 3 — Create a Dockerfile
To containerize our application for deployment we need a docker image that becomes a container at runtime. A docker image is created using a Dockerfile. A Dockerfile is just a file with a set of instructions. The Dockerfile for this project looks like this:
The last part of this Dockerfile (starting at line 23) is Streamlit specific. Dockerfile is case-sensitive and must be in the project folder with the other project files.
### 👉 Task 4–Deploy on AWS Fargate:
Follow these simple 9 steps to deploy app on AWS Fargate:
#### 👉 Step 1 — Install Docker Toolbox (for Windows 10 Home)
In order to build a docker image locally, you will need Docker installed on your computer. If you are using Windows 10 64-bit: Pro, Enterprise, or Education (Build 15063 or later) you can download Docker Desktop from [DockerHub](https://hub.docker.com/editions/community/docker-ce-desktop-windows/).
However, if you are using Windows 10 Home, you would need to install the last release of legacy Docker Toolbox (v19.03.1) from [Dockers GitHub page](https://github.com/docker/toolbox/releases).
Download and Run **DockerToolbox-19.03.1.exe** file.
The easiest way to check if the installation was successful is by opening the command prompt and typing in ‘docker’. It should print the help menu.
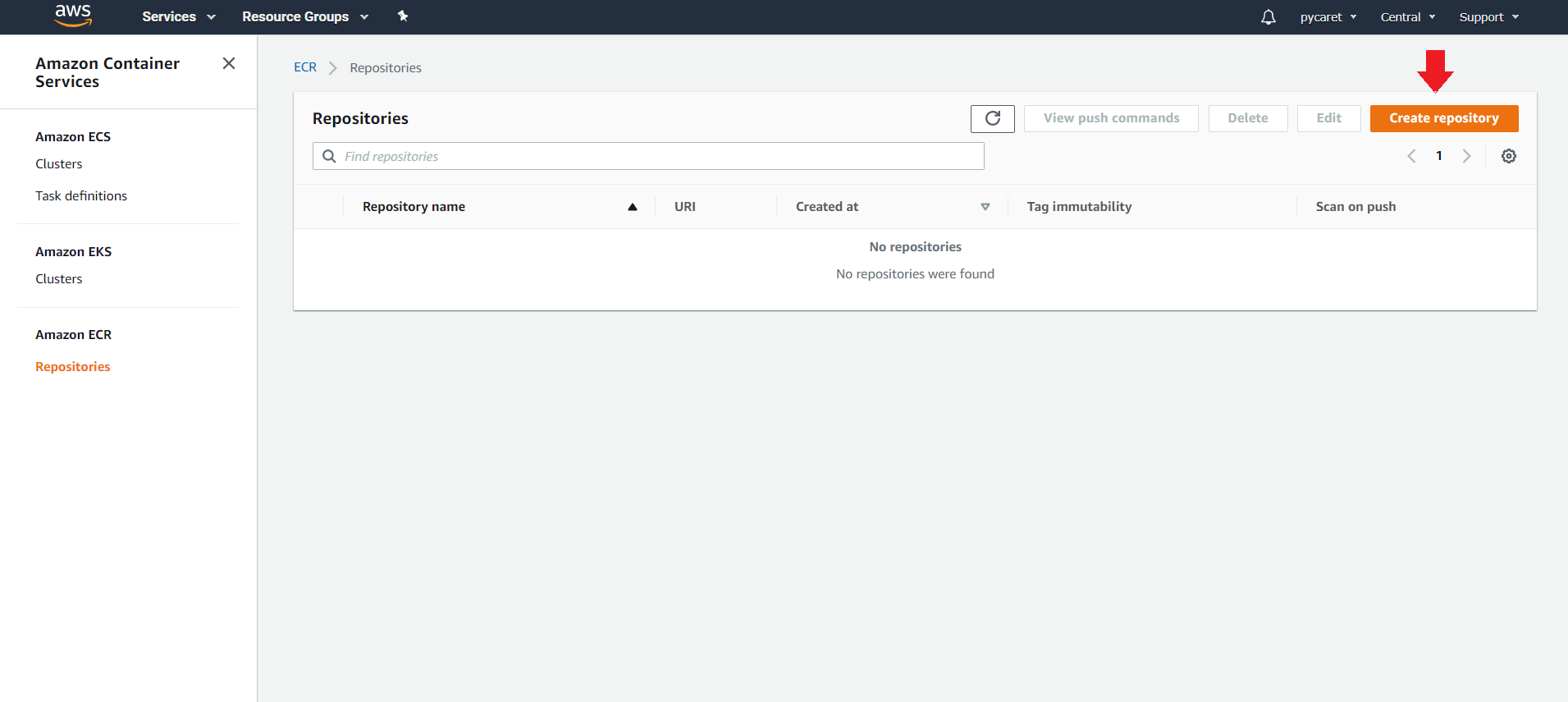
#### 👉 Step 2 — Create a Repository in Elastic Container Registry (ECR)
**(a) Login to your AWS console and search for Elastic Container Registry:**

**(b) Create a new repository:**
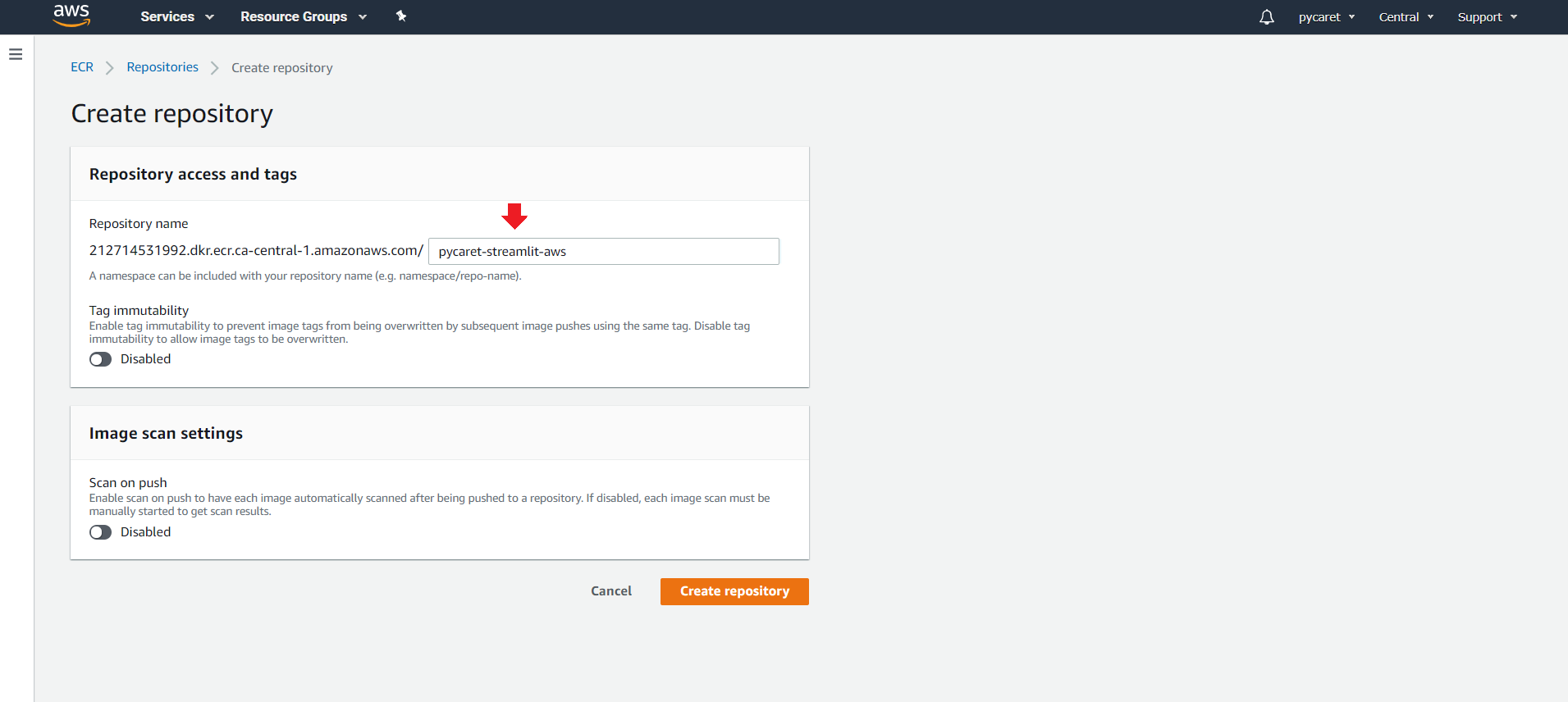
Click on “Create Repository”.
**(c) Click on “View push commands”:**
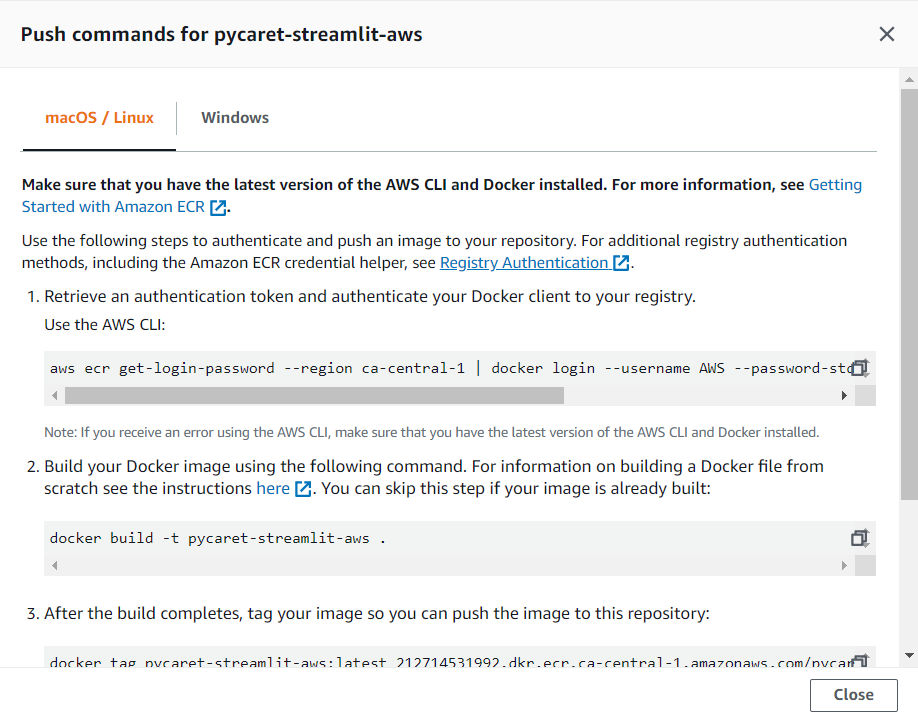
#### 👉 Step 3— Execute push commands
Navigate to your project folder using Anaconda Prompt and execute the commands you have copied in the step above. You must be in the folder where the Dockerfile and the rest of your code reside before executing these commands.
These commands are for building docker image and then uploading it on AWS ECR.
#### 👉 Step 4 — Check your uploaded image
Click on the repository you created and you will see an image URI of the uploaded image in the step above. Copy the image URI (it would be needed in step 6 below).
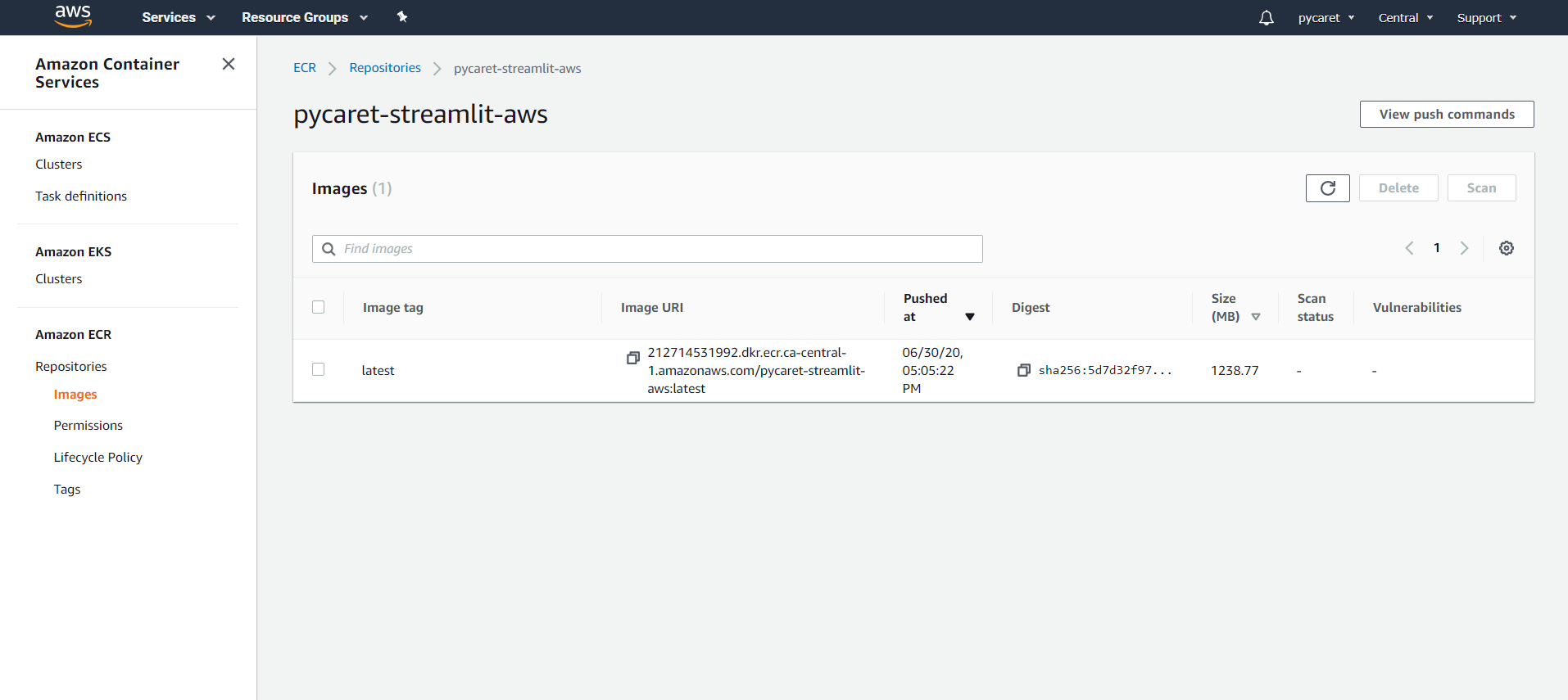
#### 👉 Step 5 — Create and Configure a Cluster
**(a) Click on “Clusters” on left-side menu:**
**(b) Select “Networking only” and click Next step:**

**(c) Configure Cluster (Enter cluster name) and click on Create:**
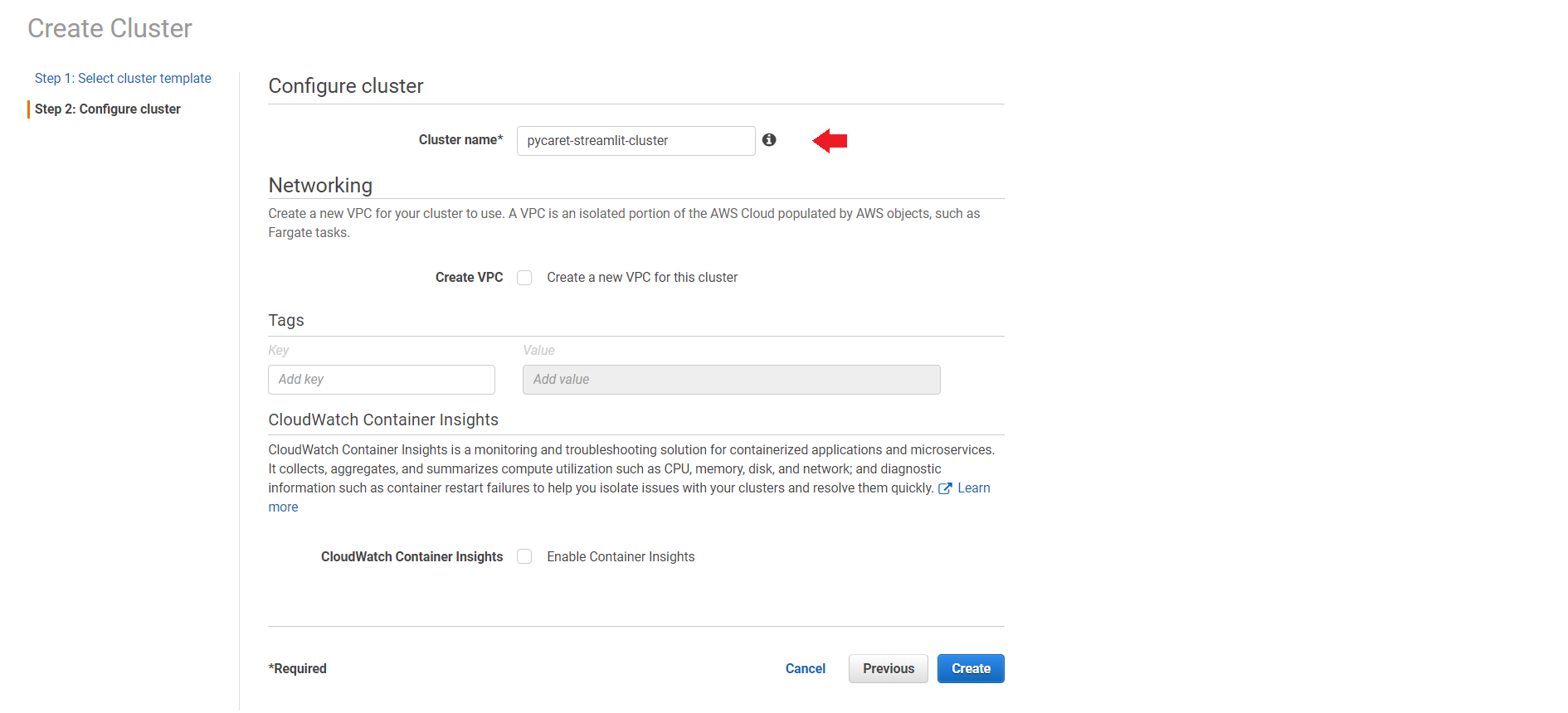
Click on “Create”.
**(d) Cluster Created:**

#### 👉 Step 6 — Create a new Task definition
A **task** definition is required to run Docker containers in Amazon ECS. Some of the parameters you can specify in a **task** definition include: The Docker image to use with each container in your **task**. How much CPU and memory to use with each **task** or each container within a **task**.
**(a) Click on “Create new task definition”:**
**(b) Select “FARGATE” as launch type:**

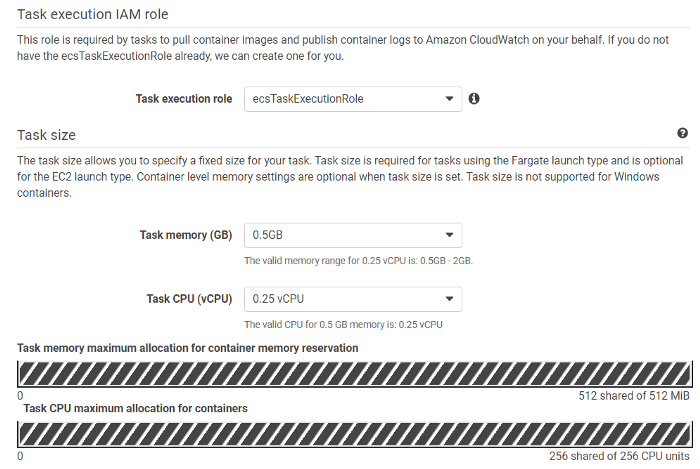
**(c) Fill in the details:**

**(d) Click on “Add Containers” and fill in the details:**

Click “Create Task” on the bottom right.

#### 👉 Step 7— Execute Task Definition
In last step we created a task that will start the container. Now we will execute the task by clicking **“Run Task”** under Actions.
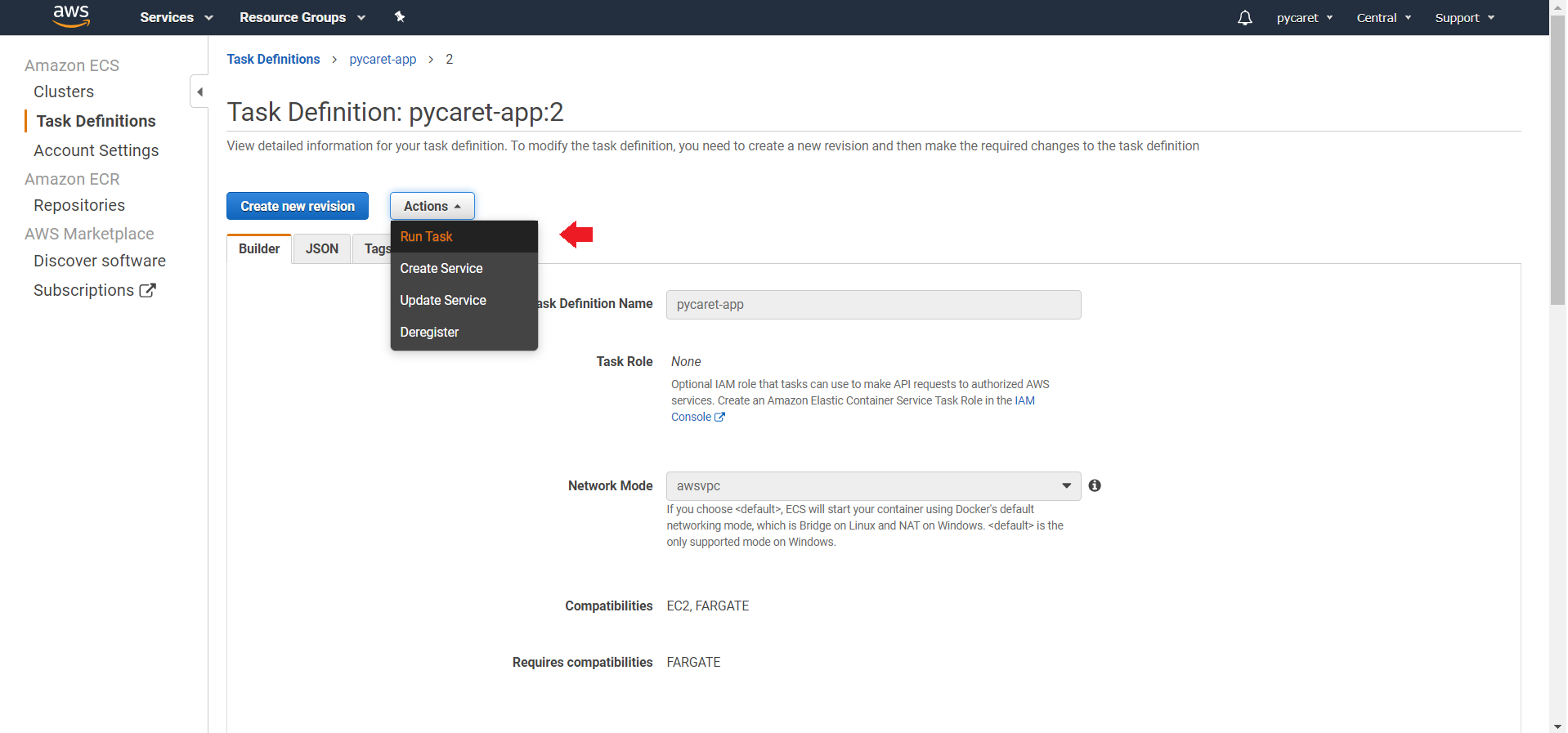
**(a) Click on “Switch to launch type” to change the type to Fargate:**
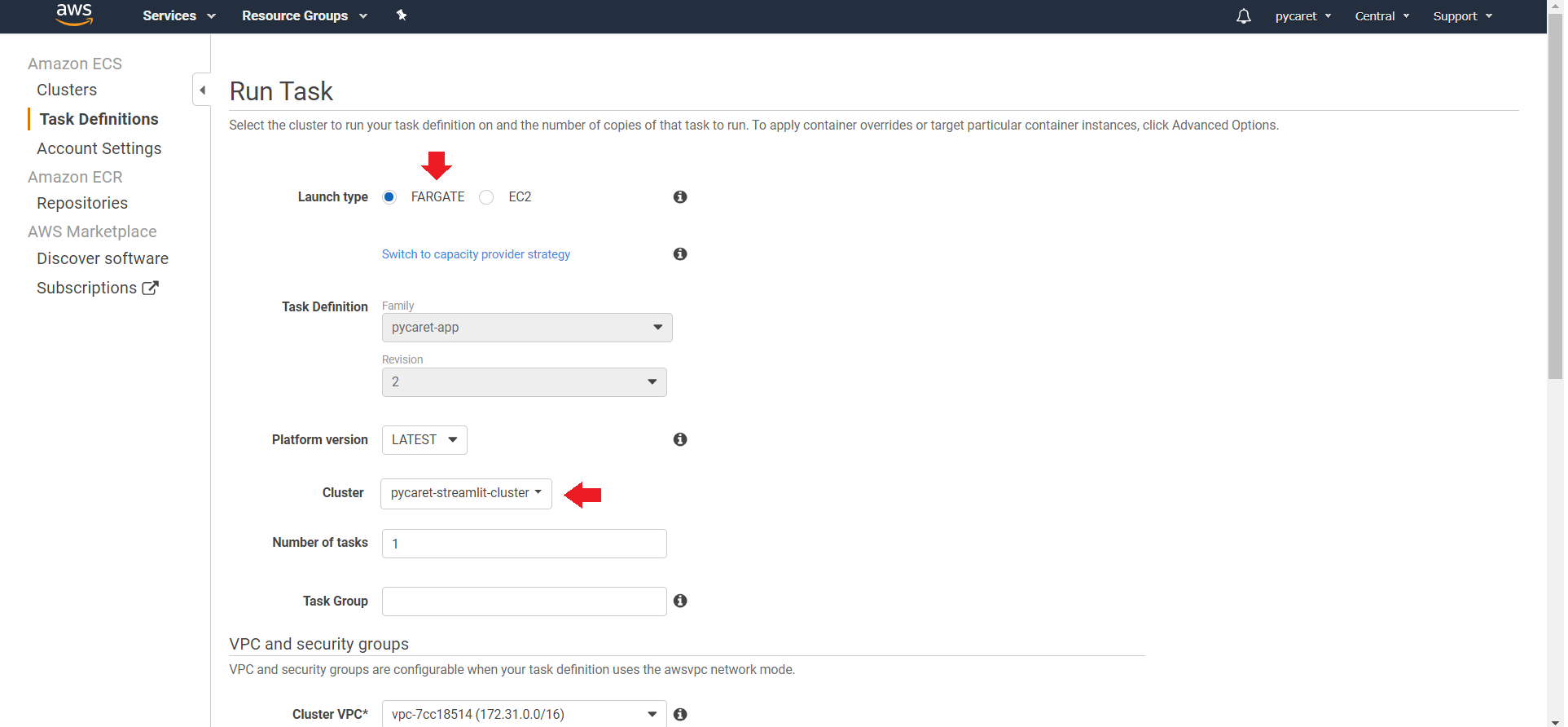
**(b) Select the VPC and Subnet from the dropdown:**

Click on “Run Task” on bottom right.
#### 👉 Step 8— Allow inbound port 8501 from Network settings
One last step before we can see our application in action on Public IP address is to allow port 8501 (used by streamlit) by creating a new rule. In order to do that, follow these steps:
**(a) Click on Task**

**(b) Click on ENI Id:**
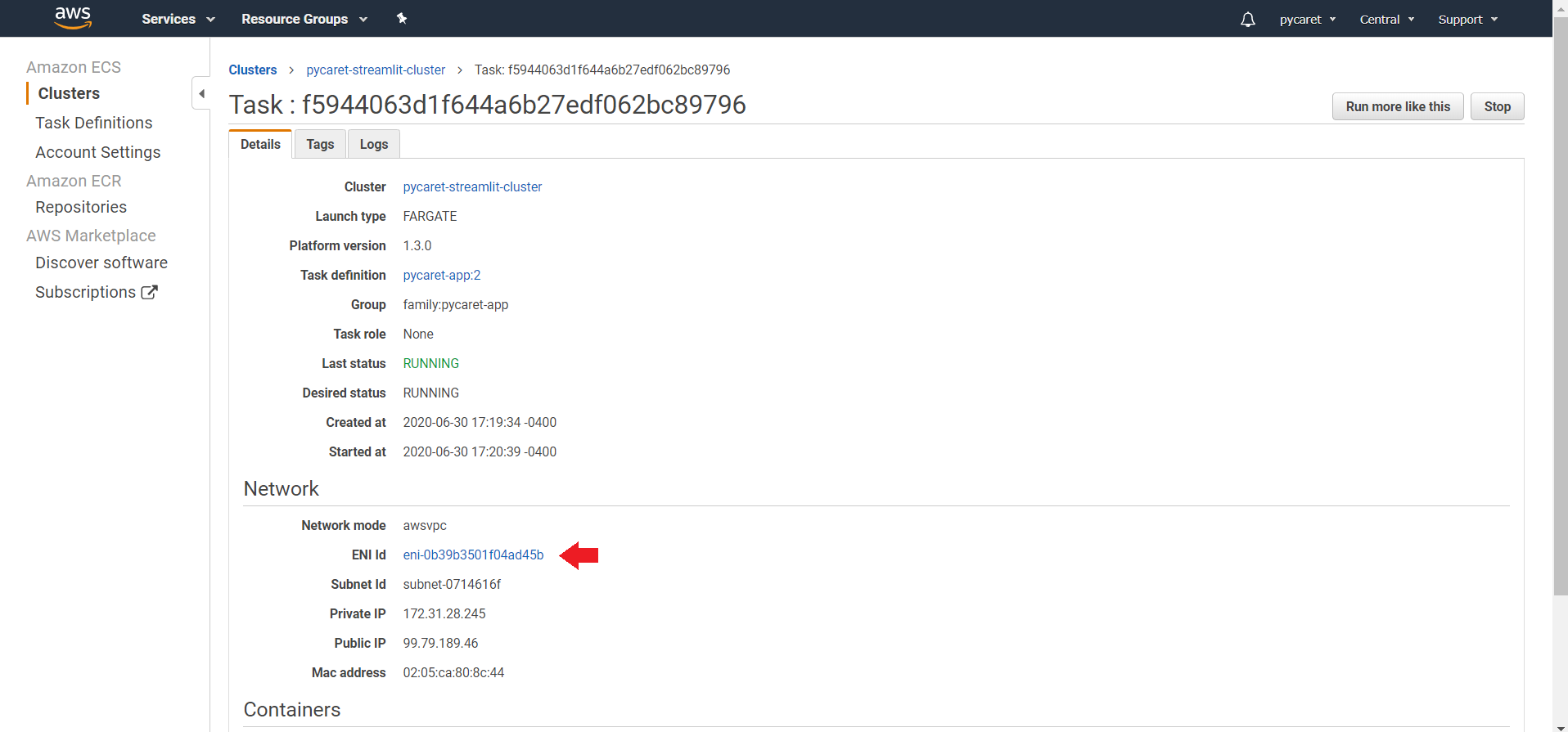
**(c) Click on Security groups**

**(d) Scroll down and click on “Edit inbound rules”**
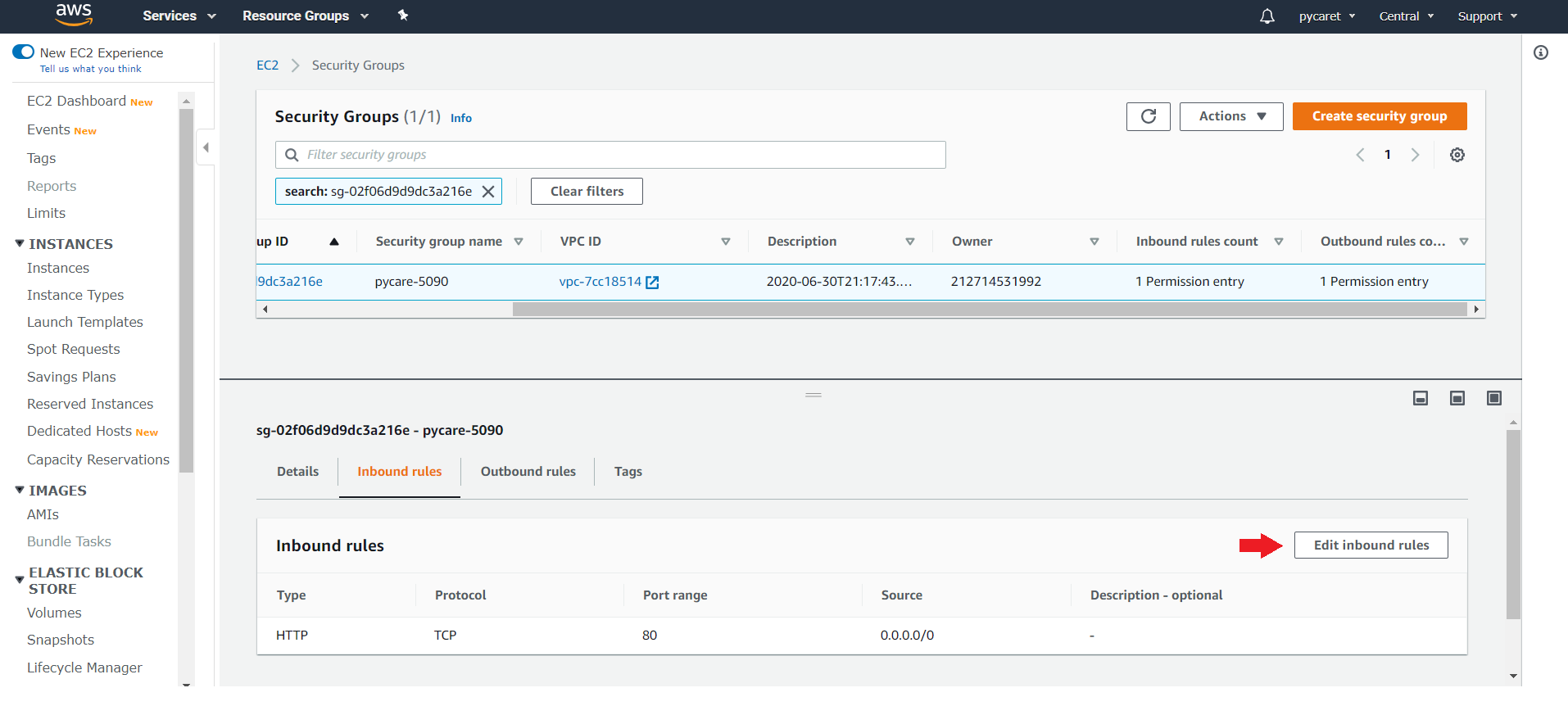
**(e) Add a Custom TCP rule of port 8501**

### 👉 Congratulations! You have published your app serverless on AWS Fargate. Use public IP address with port 8501 to access the application.
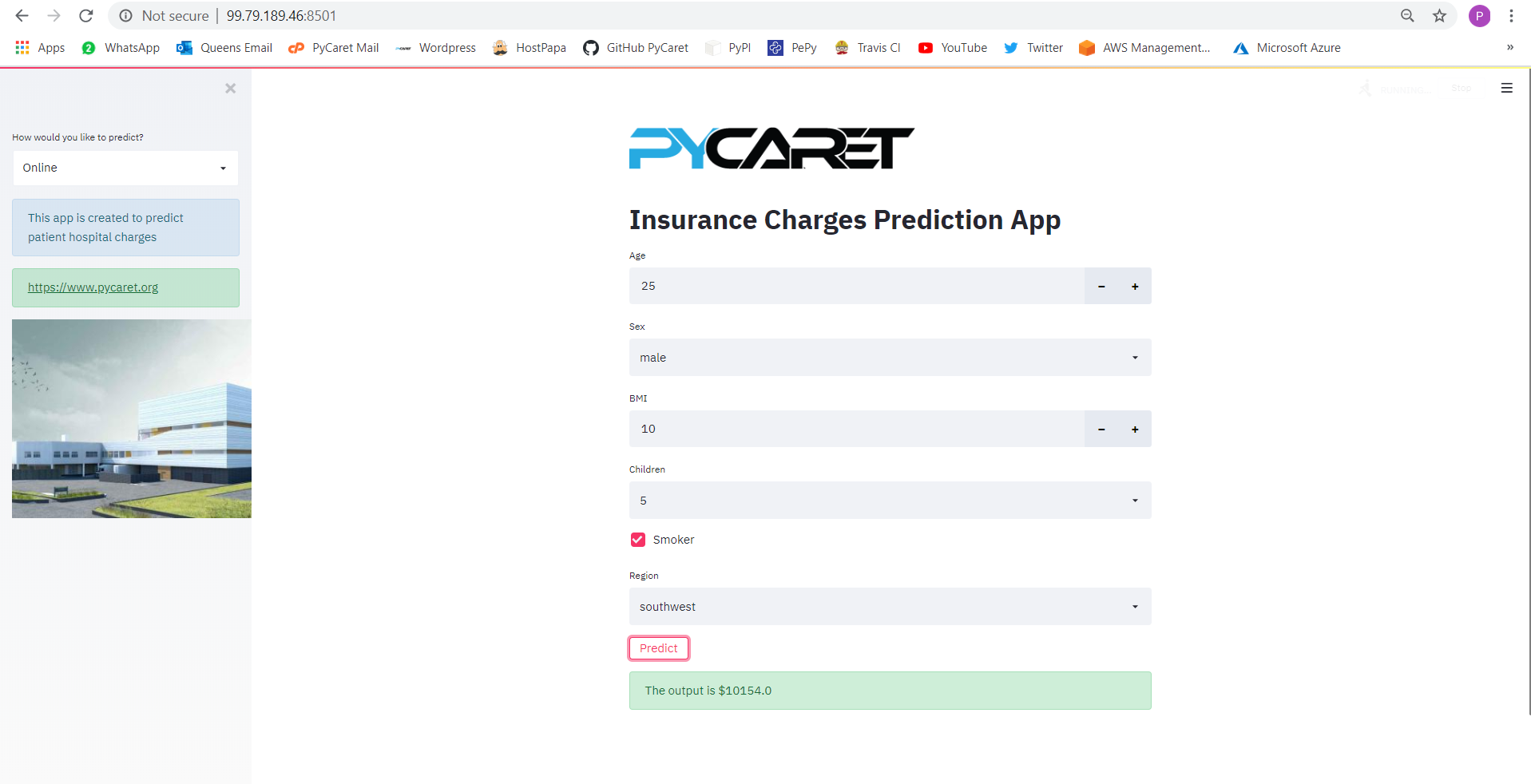
**Note:** By the time this story is published, the app will be removed from the public address to restrict resource consumption.
[Link to GitHub Repository for this tutorial](https://www.github.com/pycaret/pycaret-streamlit-aws)
[Link to GitHub Repository for Google Kubernetes Deployment](https://towardsdatascience.com/deploy-machine-learning-app-built-using-streamlit-and-pycaret-on-google-kubernetes-engine-fd7e393d99cb)
[Link to GitHub Repository for Heroku Deployment](https://towardsdatascience.com/build-and-deploy-machine-learning-web-app-using-pycaret-and-streamlit-28883a569104)
### PyCaret 2.0.0 is coming!
We have received overwhelming support and feedback from the community. We are actively working on improving PyCaret and preparing for our next release. **PyCaret 2.0.0 will be bigger and better**. If you would like to share your feedback and help us improve further, you may [fill this form](https://www.pycaret.org/feedback) on the website or leave a comment on our [GitHub ](https://www.github.com/pycaret/)or [LinkedIn](https://www.linkedin.com/company/pycaret/) page.
Follow our [LinkedIn](https://www.linkedin.com/company/pycaret/) and subscribe to our [YouTube](https://www.youtube.com/channel/UCxA1YTYJ9BEeo50lxyI_B3g) channel to learn more about PyCaret.
### Want to learn about a specific module?
As of the first release 1.0.0, PyCaret has the following modules available for use. Click on the links below to see the documentation and working examples in Python.
[Classification](https://www.pycaret.org/classification) [Regression ](https://www.pycaret.org/regression)[Clustering](https://www.pycaret.org/clustering) [Anomaly Detection ](https://www.pycaret.org/anomaly-detection)[Natural Language Processing](https://www.pycaret.org/nlp) [Association Rule Mining](https://www.pycaret.org/association-rules)
### Also see:
PyCaret getting started tutorials in Notebook:
[Classification](https://www.pycaret.org/clf101) [Regression](https://www.pycaret.org/reg101) [Clustering](https://www.pycaret.org/clu101) [Anomaly Detection](https://www.pycaret.org/anom101) [Natural Language Processing](https://www.pycaret.org/nlp101) [Association Rule Mining](https://www.pycaret.org/arul101)
### Would you like to contribute?
PyCaret is an open source project. Everybody is welcome to contribute. If you would like to contribute, please feel free to work on [open issues](https://github.com/pycaret/pycaret/issues). Pull requests are accepted with unit tests on dev-1.0.1 branch.
Please give us ⭐️ on our [GitHub repo](https://www.github.com/pycaret/pycaret) if you like PyCaret.
Medium: [https://medium.com/@moez\_62905/](https://medium.com/@moez_62905/machine-learning-in-power-bi-using-pycaret-34307f09394a)
LinkedIn:
Twitter:
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://pycaret.gitbook.io/docs/learn-pycaret/official-blog/deploy-pycaret-and-streamlit-on-aws-fargate.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.