> For the complete documentation index, see [llms.txt](https://pycaret.gitbook.io/docs/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://pycaret.gitbook.io/docs/learn-pycaret/official-blog/pycaret-2.3.6-is-here-learn-whats-new.md).
# PyCaret 2.3.6 is Here! Learn What’s New?
### 🚀 Introduction
PyCaret is an open-source, low-code machine learning library in Python that automates machine learning workflows. It is an end-to-end machine learning and model management tool that speeds up the experiment cycle exponentially and makes you more productive.
By far PyCaret 2.3.6 is the biggest release in terms of the new features and functionalities. This article demonstrates the use of new functionalities added in the recent release of [PyCaret 2.3.6](https://pycaret.gitbook.io/docs/get-started/release-notes#pycaret-2.3.6).
### 💻 Installation
Installation is easy and will only take a few minutes. PyCaret’s default installation from pip only installs hard dependencies as listed in the [requirements.txt](https://github.com/pycaret/pycaret/blob/master/requirements.txt) file.
```
pip install pycaret
```
To install the full version:
```
pip install pycaret[full]
```
### 📈 Dashboard
This function will generate the interactive dashboard for a trained model. The dashboard is implemented using the [ExplainerDashboard](http://explainerdashboard.readthedocs.io/).
```
# load dataset
from pycaret.datasets import get_data
data = get_data('iris')
# init setupfrom pycaret.classification import *
s = setup(data, target = 'species', session_id = 123)
# train model
lr = create_model('lr')
# generate dashboard
dashboard(lr)
```
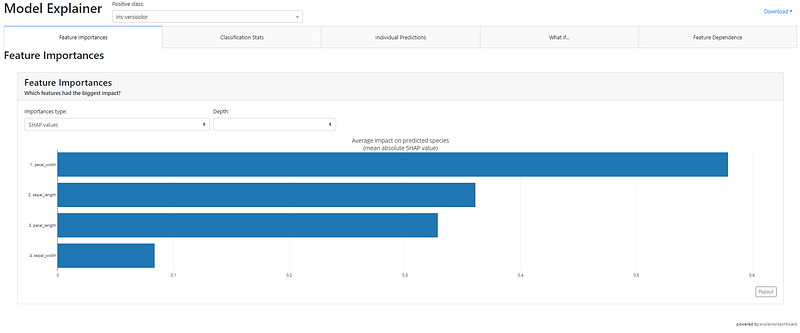
**Video Demo:**
{% embed url="" %}
### 📊 Exploratory Data Analysis (EDA)
This function will generate automated EDA using the [AutoViz](https://github.com/AutoViML/AutoViz) integration.
```
# load dataset
from pycaret.datasets import get_data
data = get_data('iris')
# init setup
from pycaret.classification import *
s = setup(data, target = 'species', session_id = 123)
# generate EDA
eda()
```
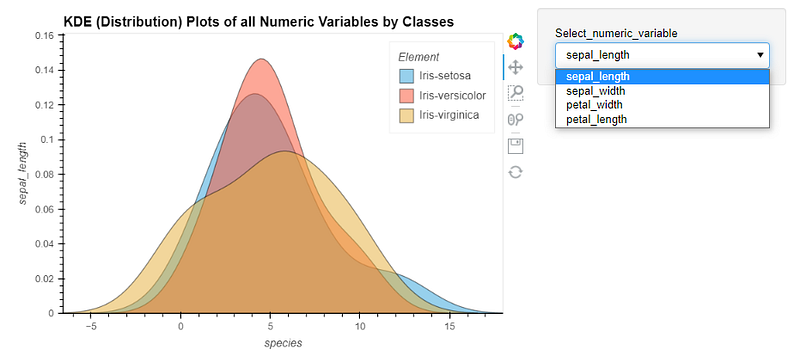
**Video Demo:**
{% embed url="" %}
### 🚊 Convert Model
This function will transpile trained machine learning models into native inference scripts in different programming languages (Python, C, Java, Go, JavaScript, Visual Basic, C#, PowerShell, R, PHP, Dart, Haskell, Ruby, F#). This functionality is very useful if you want to deploy models into environments where you can’t install your normal Python stack to support model inference.
```
# load dataset
from pycaret.datasets import get_data
data = get_data('iris')
# init setup
from pycaret.classification import *
s = setup(data, target = 'species', session_id = 123)
# train model
lr = create_model('lr')
# convert model
lr_java = convert_model(lr, language = 'java')
print(lr_java)
```

**Video Demo:**
{% embed url="" %}
### ☑️ Check Fairness
There are many approaches to conceptualizing fairness. This new function follows the approach known as [group fairness](https://github.com/fairlearn/fairlearn), which asks: Which groups of individuals are at risk for experiencing harm. This function provides fairness-related metrics between different groups (also called subpopulations).
```
# load dataset
from pycaret.datasets import get_data
data = get_data('income')
# init setup
from pycaret.classification import *
s = setup(data, target = 'income >50K', session_id = 123)
# train model
lr = create_model('lr')
# check fairness
check_fairness(lr, sensitive_features = ['race'])
```

**Video Demo:**
{% embed url="" %}
### 📩 Create Web API
This function will create a POST API for the ML pipeline for inference using [FastAPI](https://github.com/tiangolo/fastapi) framework. It only creates the API and doesn’t run it automatically.
```
# load dataset
from pycaret.datasets import get_data
data = get_data('iris')
# init setup
from pycaret.classification import *
s = setup(data, target = 'species', session_id = 123)
# train model
lr = create_model('lr')
# create API
create_api(lr, 'my_first_api')
# Run the API
!python my_first_api.py
```


#### **Video Demo:**
{% embed url="" %}
### 🚢 Create Docker
This function will create a `Dockerfile`and `requirements`file for your API end-point.
```
# load dataset
from pycaret.datasets import get_data
data = get_data('iris')
# init setup
from pycaret.classification import *
s = setup(data, target = 'species', session_id = 123)
# train model
lr = create_model('lr')
# create API
create_api(lr, 'my_first_api')
# create Docker
create_docker('my_first_api')
```

**Video Demo:**
{% embed url="" %}
### 💻 Create Web Application
This function creates a basic [Gradio](https://github.com/gradio-app/gradio) web app for inference. It will later be expanded for other app types such as Streamlit.
```
# load dataset
from pycaret.datasets import get_data
data = get_data('iris')
# init setup
from pycaret.classification import *
s = setup(data, target = 'species', session_id = 123)
# train model
lr = create_model('lr')
```

**Video Demo:**
{% embed url="" %}
### 🎰 Monitor Drift of ML Models
A new parameter called `drift_report` is added to the `predict_model` function that generates the drift report using [Evidently AI](https://github.com/evidentlyai/evidently?) framework. At the moment this functionality is in experimental mode and will only work on test data. Later on, it will be expanded for production use.
```
# load dataset
from pycaret.datasets import get_data
data = get_data('iris')
# init setup
from pycaret.classification import *
s = setup(data, target = 'species', session_id = 123)
# train model
lr = create_model('lr')
# generate report
preds = predict_model(lr, drift_report = True)
```


**Video Demo:**
{% embed url="" %}
### 🔨 Plot Model is now more configurable
`plot_model` function is PyCaret is now more configurable. For example, previously if you wanted to see percentages in Confusion Matrix instead of absolute numbers, it wasn’t possible, or if you want to change the color map of visuals, it wasn’t possible. Now it is possible with the new parameter `plot_kwargs` in the `plot_model` function. See example:
```
# load dataset
from pycaret.datasets import get_data
data = get_data('iris')
# init setup
from pycaret.classification import *
s = setup(data, target = 'species', session_id = 123)
# train model
lr = create_model('lr')
# plot model (without plot kwargs)
plot_model(lr, plot = 'confusion_matrix')
# plot model (with plot kwargs)
plot_model(lr, plot = 'confusion_matrix', plot_kwargs = {'percent' : True})
```

### 🏆Optimize Threshold
This is not a new function but it was completely revamped in 2.3.6. This function is to optimize the probability threshold for binary classification problems. Previously you had to pass cost function as `true_positive` , `false_positive` , `true_negative` , `false_negative` in this function and now it automatically picks up all the metrics including the custom ones from your active experiment run.
```
# load dataset
from pycaret.datasets import get_data
data = get_data('blood')
# init setup
from pycaret.classification import *
s = setup(data, target = 'Class', session_id = 123)
# train model
lr = create_model('lr')
# optimize threshold
optimize_threshold(lr)
```

### 📚 New Documentation
The biggest and hardest of all is the completely new documentation. This is a single source of truth for everything related to PyCaret, from official tutorials to release notes and from API ref to community contributions. Take a video tour:
{% embed url="" %}
Finally, if you want to take the tour of all new functionalities added in 2.3.6, watch this 10 minutes video:
{% embed url="" %}
To learn about all the other changes, bug fixes, and minor updates in PyCaret 2.3.6, check out the detailed [release notes](https://github.com/pycaret/pycaret/releases/tag/2.3.6).
Thank you for reading.
### :link: Important Links
* 📚 [Official Docs:](https://pycaret.gitbook.io/) The bible of PyCaret. Everything is here.
* 🌐 [Official Web:](https://www.pycaret.org/) Check out our official website
* 😺 [GitHub](https://www.github.com/pycaret/pycaret) Check out our Git
* ⭐ [Tutorials](https://pycaret.gitbook.io/docs/get-started/tutorials) New to PyCaret? Check out our official notebooks!
* 📋 [Example Notebooks](https://github.com/pycaret/pycaret/tree/master/examples) created by the community.
* 📙 [Blog](https://pycaret.gitbook.io/docs/learn-pycaret/official-blog) Tutorials and articles by contributors.
* ❓ [FAQs](https://pycaret.gitbook.io/docs/learn-pycaret/faqs) Check out frequently asked questions.
* 📺 [Video Tutorials](https://pycaret.gitbook.io/docs/learn-pycaret/videos) Our video tutorial from various events.
* 📢 [Discussions](https://github.com/pycaret/pycaret/discussions) Have questions? Engage with community and contributors.
* 🛠️ [Changelog](https://pycaret.gitbook.io/docs/get-started/release-notes) Changes and version history.
* 🙌 [User Group](https://www.meetup.com/pycaret-user-group/) Join our Meetup user group.
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://pycaret.gitbook.io/docs/learn-pycaret/official-blog/pycaret-2.3.6-is-here-learn-whats-new.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.